
Makine Öğrenmesine Giriş: Bilgisayarlar Nasıl Öğrenir?
Makine öğrenmesi, bilgisayarların doğrudan programlanmadan, verilerdeki örüntüleri keşfederek kendi kendine öğrenmesini sağlayan bir yapay zekâ yöntemidir. Bu yaklaşımda sistem, büyük miktarda veriyi analiz eder, bu verilerden anlam çıkarır ve yeni durumlarla karşılaştığında daha önce öğrendiklerine dayanarak tahminlerde bulunabilir. Böylece model yalnızca ezber yapan bir yapı olmaktan çıkar; çevresine uyum sağlayan, öğrenen ve genelleme yapabilen bir mekanizma hâline gelir.

Bugün kullandığımız pek çok teknoloji —arama motorları, yüz tanıma sistemleri, öneri motorları, tıbbi görüntüleme çözümleri ve daha fazlası— makine öğrenmesinin bu özelliği sayesinde hayatımıza girmiştir. Temel süreç, verinin toplanması, bu veriyle modelin eğitilmesi ve eğitilen modelin yeni veriler üzerinde test edilmesi olarak özetlenebilir.
Makine öğrenmesinin dünyası geniştir; ancak temel olarak dört ana yaklaşım üzerine kuruludur: denetimli öğrenme, denetimsiz öğrenme, yarı denetimli öğrenme ve pekiştirmeli öğrenme. Bu yazıda, bu dört yöntemin mantığını, ne zaman kullanıldığını ve birbirlerinden nasıl ayrıldıklarını adım adım inceleyerek makine öğrenmesine kapsamlı bir giriş yapacağız.
Şimdi, bu yöntemlerin ilki olan denetimli öğrenmeye daha yakından bakalım.
Denetimli Öğrenme (Supervised Learning)
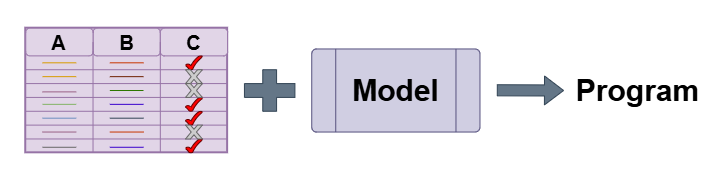
Yukarıdaki şekilden de anlaşılacağı gibi, denetimli öğrenme (supervised learning), makine öğrenmesinin en temel ve en yaygın kullanılan yaklaşımıdır. Bu yöntemde model, giriş verileriyle birlikte doğru çıktıları yani etiketleri içeren bir veri kümesiyle eğitilir. Böylece model, örneklerden hareketle genelleme yapmayı öğrenir. Şeklin sol tarafında gördüğünüz gibi, elimizde sınıfları (örneğin “A”, “B”, “C” ya da örnek uygulamalarda “Elma”, “Portakal” gibi etiketler) belli olan bir etiketli veri tablosu vardır. Bu veriler modelin öğrenmesi için temel oluşturur.
Eğitim aşamasında model, her giriş ile onun doğru etiketini eşleştirerek, içsel parametrelerini ayarlar. Bu süreç, tahmin edilen değer ile gerçek etiket arasındaki hatanın minimize edilmesine dayanır. En sık kullanılan denetimli öğrenme algoritmaları arasında Doğrusal Regresyon, Lojistik Regresyon, Karar Ağaçları, Destek Vektör Makineleri (SVM) ve Yapay Sinir Ağları bulunur. Bu algoritmalar, veri ile etiket arasındaki ilişkiyi farklı matematiksel modellerle temsil eder.
Eğitim tamamlandıktan sonra model, şeklin sağ kısmında görülen “Program” hâline gelir; yani artık yeni veriler üzerinde otomatik olarak doğru tahminler üretebilir. Bu nedenle denetimli öğrenme, gerçek dünyadaki pek çok uygulamada — hastalık teşhisi, spam e-posta tespiti, fiyat tahmini, duygu analizi ve görüntüde nesne tanıma gibi — kritik bir rol oynar.
Sonuç olarak denetimli öğrenme, veri ve etiket ilişkisini sistematik biçimde öğrenerek güçlü bir tahmin mekanizması geliştirir ve bu yönüyle makine öğrenmesinin merkezinde yer alır.
Denetimli öğrenme, etiketli verilerle çalıştığı için güçlü ve güvenilir sonuçlar üretir; ancak her zaman etiketli veri bulmak mümkün olmayabilir. İşte bu noktada, verilerin kendi yapısından yararlanan denetimsiz öğrenme yöntemleri devreye girer. Şimdi bu ikinci yaklaşmaya daha yakından bakalım.
Denetimsiz Öğrenme (Unsupervised Learning)
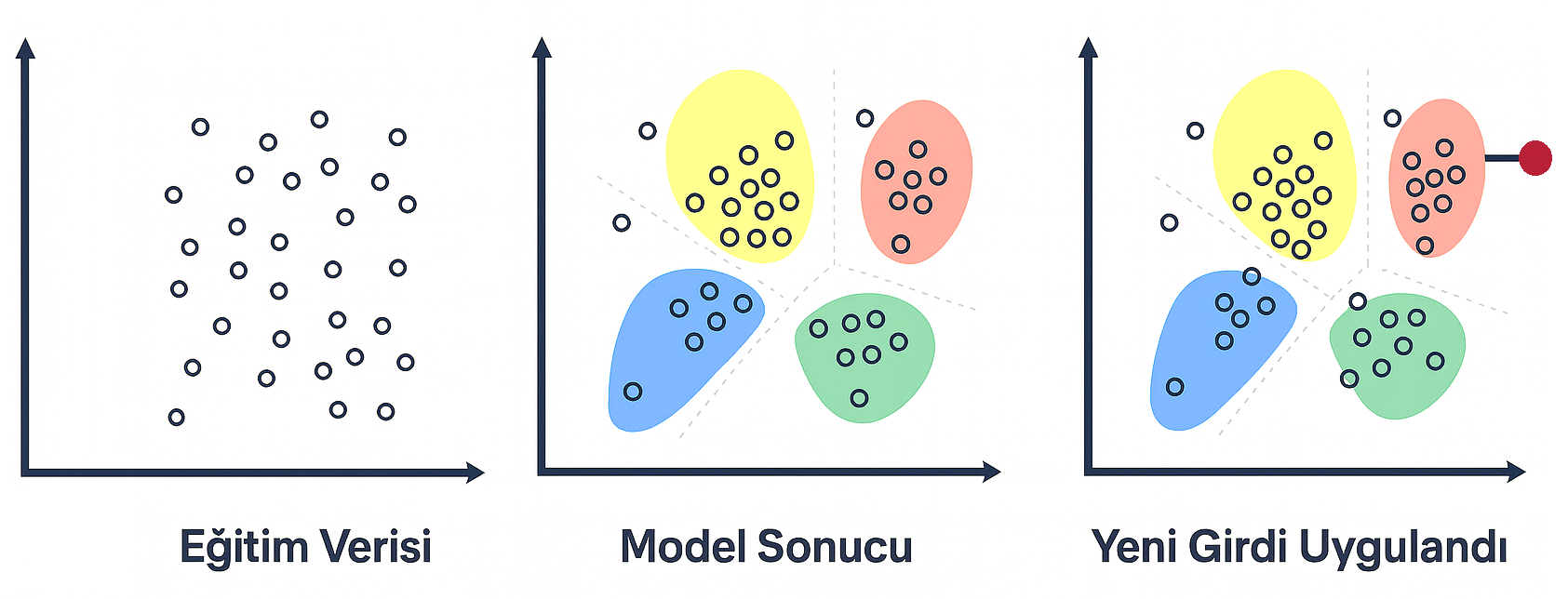
Yukarıdaki görselden de anlaşılacağı gibi, denetimsiz öğrenmede modelin elinde etiketlenmiş bir veri bulunmaz; yalnızca ham veri vardır. Model, bu veriyi kendi başına inceleyerek veriler arasındaki benzerlikleri, ayrılıkları veya tekrar eden yapıları keşfetmeye çalışır. Şeklin ilk panelinde görülen dağınık noktalar, herhangi bir sınıf etiketi olmadan bir araya gelmiş verileri temsil eder. Bu aşamada modelin niyeti, verinin doğal yapısını anlamaktır.
İkinci panelde gösterildiği gibi, model bu ham veriyi analiz ettikten sonra benzer özelliklere sahip noktaları kümeler hâline getirir. Bu kümeler, verinin zaten içinde var olan ancak bizim dışarıdan etiketlenmemiş hâlde göremediğimiz doğal gruplardır. K-means, DBSCAN veya Hiyerarşik Kümeleme gibi algoritmalar bu süreci yönetmek için kullanılır. Bu yöntemler, verinin şekline göre optimal gruplar oluşturarak veri içindeki gizli düzeni ortaya çıkarır.
Üçüncü panel ise bu modelin gerçek hayatta nasıl kullanılabileceğini gösterir: Model, yeni gelen bir veriyi aldığı anda hangi kümeye en çok benzediğini tespit eder ve ilgili gruba atar. Bu, örneğin bir e-ticaret sitesinin müşterileri otomatik segmentlere ayırması veya bir güvenlik sisteminin anormal davranışları tespit etmesi gibi pek çok uygulamada kritik bir rol oynar.
Denetimli ve denetimsiz öğrenmenin temel mantığını artık gördüğümüze göre, bu iki yaklaşımın bir arada kullanıldığı yarı denetimli öğrenme yöntemine geçebiliriz.
Yarı Denetimli Öğrenme (Semi-Supervised Learning)
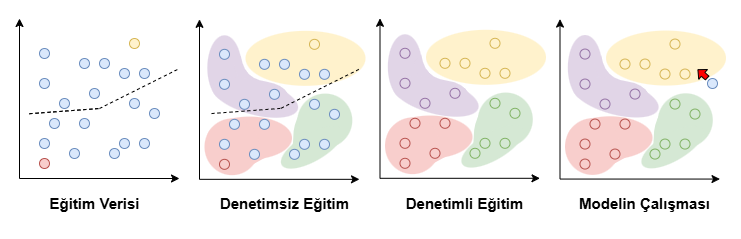
Yarı denetimli öğrenme, çok büyük miktarda veriye sahip olup bunların yalnızca küçük bir kısmının etiketli olduğu durumlarda kullanılan son derece pratik bir yaklaşımdır. Günümüzde pek çok uygulamada veriyi toplamak kolaydır; fakat bu verileri elle etiketlemek hem maliyetli hem de zaman açısından sürdürülemez olabilir. Örneğin bir sağlık projesinde binlerce tıbbi görüntü toplanabilir, ancak bu görüntülerin uzmanlar tarafından tek tek sınıflandırılması ciddi bir iş gücü gerektirir. Bu nedenle gerçek veri kümelerinde genellikle “etiketsiz çok, etiketli az” durumu ortaya çıkar.
Yukarıdaki görsel de bu süreci adım adım yansıtmaktadır. İlk panelde yalnızca birkaç örneğin etiketli, geri kalan çoğunluğun ise etiketsiz olduğu görülür. İkinci panelde model, etiketsiz verinin doğal yapısını fark ederek veriyi kümelere ayırır; bu adım tamamen denetimsiz öğrenmenin gücünü kullanır. Üçüncü panelde bu kümelerdeki az sayıdaki etiketli veri devreye girer ve model, her grubun özelliklerini daha doğru şekilde öğrenir. Son panelde ise yeni bir veri noktası sisteme eklenir ve model hem kümelerin genel yapısını hem de mevcut etiketli örnekleri kullanarak bu veriyi doğru sınıfa yerleştirir.
Bu nedenle yarı denetimli öğrenme, az etiketle maksimum bilgi elde etmeyi sağlayan, özellikle tıp, doğal dil işleme ve büyük ölçekli görüntü sınıflandırma gibi alanlarda güçlü bir yaklaşımdır.
Denetimli, denetimsiz ve yarı denetimli yöntemlerde model, ne kadar farklı teknik kullanılırsa kullanılsın, sonuçta var olan veriyi analiz ederek öğrenir. Ancak bazı problemler vardır ki veri hazır değildir; modelin neyin doğru neyin yanlış olduğunu deneyerek öğrenmesi gerekir. İşte bu noktada, önceki yöntemlerin kapsayamadığı bu ihtiyacı karşılayan pekiştirmeli öğrenme devreye girer. Şimdi, kararlarını ödül ve ceza mekanizmasıyla şekillendiren bu yeni öğrenme yaklaşımını inceleyelim.
Pekiştirmeli Öğrenme (Reinforcement Learning)
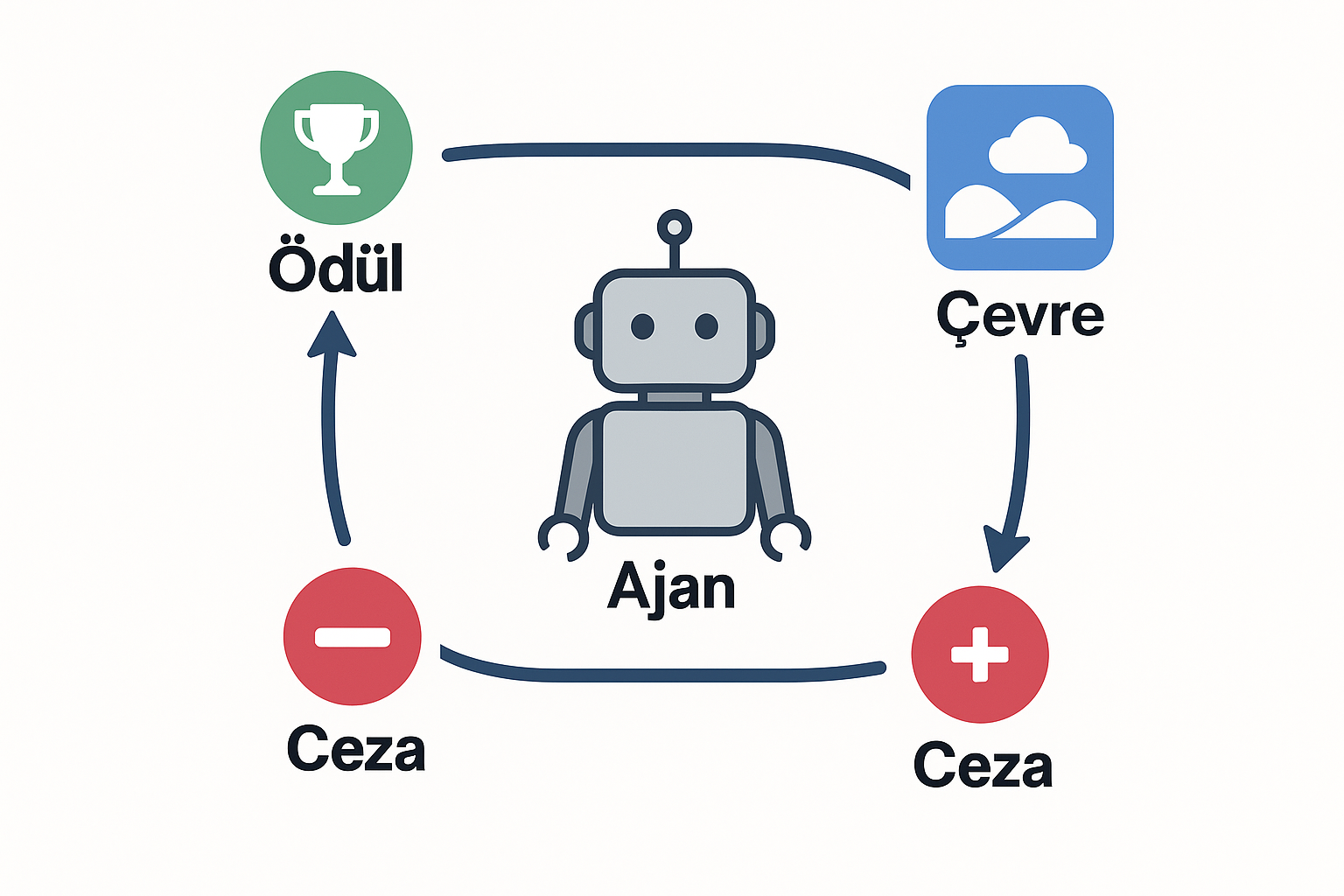
Pekiştirmeli öğrenme, klasik makine öğrenmesi yaklaşımlarından farklı olarak modelin mevcut veriyi analiz etmesine değil, deneyim kazanarak öğrenmesine dayanır. Bu yöntemde bir “ajan”, içinde bulunduğu ortama eylemler yaparak karşılık verir ve her eylemin sonucunda bir geri bildirim alır. Bu geri bildirim genellikle olumlu bir “ödül” ya da olumsuz bir “ceza” şeklindedir. Ajanın temel amacı, uzun vadede toplam ödülünü maksimize edecek davranış biçimini keşfetmektir.
Ajan her adımda yeni bir durumla karşılaşır, bir eylem seçer ve sonucunda aldığı ödül ya da ceza doğrultusunda politika denilen karar verme stratejisini günceller. Bu süreç sürekli tekrarlandığı için ajan zaman içinde kendi deneyimlerinden “neyin işe yarayıp neyin yaramadığını” anlayabilir. Pekiştirmeli öğrenmeyi güçlü kılan nokta, bu süreçte doğru davranışların açıkça öğretilmesine gerek olmamasıdır; model, çevreyle etkileşip sonuçları gözlemleyerek en uygun stratejiyi kendi kendine keşfeder.
Bu yaklaşım, karar verme sürecinin adım adım ilerlediği ve geri bildirimin doğrudan veri etiketleriyle değil, yapılan eylemlerin sonuçlarıyla belirlendiği problemler için oldukça etkilidir. Örneğin otonom araçların hız, dönüş veya frenleme kararlarını vermesi, robotların engeller arasında en iyi rotayı planlaması, bir yapay zekâ oyuncusunun satranç ya da Go gibi oyunlarda strateji geliştirmesi hep bu prensip üzerine kuruludur. Enerji tüketimi optimizasyonu, kaynak yönetimi ve kontrol sistemleri gibi alanlarda da pekiştirmeli öğrenme giderek daha fazla kullanılmaktadır.
Özet
Makine öğrenmesi, bilgisayarların verilerden anlam çıkararak karar verebilmesini sağlayan güçlü bir teknolojidir. Bu alanda kullanılan dört temel yaklaşım, farklı veri koşullarına ve problem türlerine göre avantaj sunar. Denetimli öğrenme, etiketli verilerin bulunduğu durumlarda en doğru tahminleri üretir; model, örneklerden yola çıkarak veri–etiket ilişkisini öğrenir. Buna karşın denetimsiz öğrenme, etiketlerin olmadığı durumlarda verinin doğal yapısını keşfetmeye odaklanır ve gizli kümeleri, ilişkileri ortaya çıkarır.
Gerçek hayatta çoğu zaman veriler çok, etiketler az olduğundan yarı denetimli öğrenme, bu iki yaklaşımın güçlü yönlerini birleştirerek daha yüksek doğruluk sunan bir ara çözüm sağlar. Az miktardaki etiketli örnek, geniş etiketsiz veriyle birlikte kullanılarak modelin daha iyi genelleme yapması sağlanır.
Son olarak, pekiştirmeli öğrenme diğer üç yöntemden ayrılır; çünkü burada öğrenme, hazır veriye değil, çevreyle etkileşim üzerinden alınan ödül ve cezalara dayanır. Bu dört yöntemi bir arada düşündüğümüzde, makine öğrenmesinin farklı problem türlerine uyum sağlayabilen esnek ve çok yönlü bir yapıya sahip olduğu açıkça görülür.